
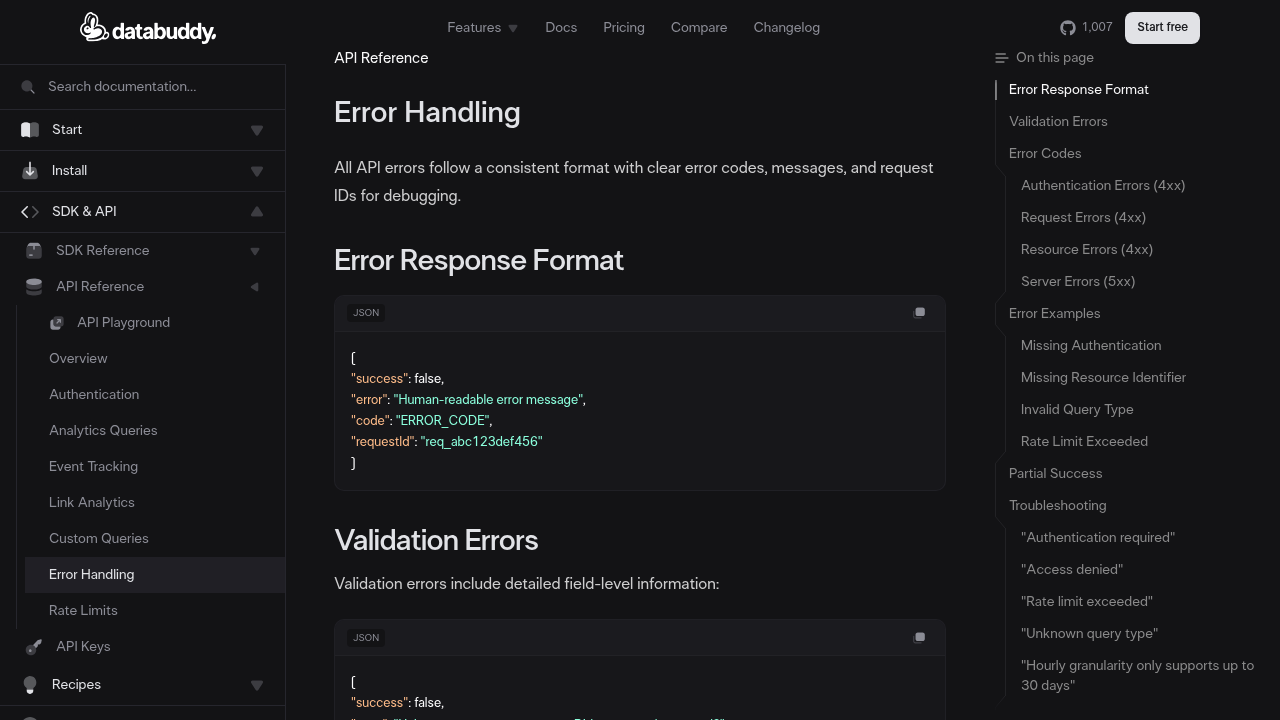
Error tracking and user privacy seem like they're pulling in opposite directions. Your engineers need stack traces, exception context, and enough runtime detail to reproduce a bug. Meanwhile, GDPR Article 5(1)(c) requires that personal data be "adequate, relevant and limited to what is necessary" — a standard that raw error logs routinely fail.
The tension is real, but it's resolvable. The key is designing your error telemetry pipeline around data minimization from the start, rather than bolting on scrubbing rules after the fact.
Why error logs are a privacy risk by default
Most application errors don't arrive clean. A TypeError thrown inside a payment form might include the full request body. An unhandled promise rejection in a user settings flow might serialize the user object — name, email, internal ID and all — into the stack trace locals. Node.js uncaughtException handlers often receive errors that carry database query strings containing literal user input.
Under GDPR Recital 30, IP addresses are explicitly classified as online identifiers and constitute personal data. Under CCPA (California Civil Code §1798.140), the definition of "personal information" covers unique identifiers including IP addresses. That means even a minimally-instrumented error event — exception type, URL, timestamp, IP — can qualify as processing personal data and trigger all the attendant obligations.
The OWASP Logging Cheat Sheet puts the design principle plainly: sensitive data (passwords, authentication tokens, PII, health data, financial identifiers) should never appear in logs. Not masked later — never logged in the first place. That's the standard a privacy-first implementation must meet.
The four-layer architecture for compliant error tracking
Handling error tracking in a privacy-first analytics platform isn't a single configuration toggle. It requires controls at four distinct layers.
Layer 1: SDK-level sanitization before transmission
The most reliable place to strip PII is the SDK callback that fires before any data leaves the browser or server process. In Sentry's JavaScript SDK, this is beforeSend. In OpenTelemetry, it's an in-process processor applied to your LogRecord or SpanEvent before export.
For browser-side error capture, the pattern looks like:
// window.onerror / unhandledrejection handler
window.addEventListener('unhandledrejection', (event) => {
const sanitized = sanitizeError(event.reason);
errorClient.captureException(sanitized);
});
function sanitizeError(err) {
// Strip email addresses from the message string
err.message = err.message?.replace(
/[a-zA-Z0-9._%+\-]+@[a-zA-Z0-9.\-]+\.[a-zA-Z]{2,}/g,
'[EMAIL]'
);
// Strip credit card patterns
err.message = err.message?.replace(
/\b\d{4}[\s\-]?\d{4}[\s\-]?\d{4}[\s\-]?\d{4}\b/g,
'[CARD]'
);
return err;
}
For Sentry specifically, setting sendDefaultPii: false (the default) prevents automatic attachment of cookies, HTTP headers, and the authenticated user object. A beforeSend hook then handles any PII that can appear contextually inside exception values or stack trace locals.
On the server side — particularly in Node.js environments — process.on('uncaughtException', ...) and process.on('unhandledRejection', ...) handlers should apply the same sanitization before forwarding to any third-party error sink.
Layer 2: Collector-level redaction before storage
If you're running an OpenTelemetry pipeline (which any team running at scale should be), the Collector is the natural enforcement boundary. The contrib redactionprocessor takes an allowlist approach: it deletes any span, log, or metric attributes not on an explicitly approved list, and masks values that match blocked regex patterns.
processors:
redaction:
allow_all_keys: false
allowed_keys:
- service.name
- service.version
- exception.type
- exception.stacktrace
- http.status_code
- http.method
- http.route
blocked_values:
- '[a-zA-Z0-9._%+\-]+@[a-zA-Z0-9.\-]+\.[a-zA-Z]{2,}' # emails
- '\b(?:\d{1,3}\.){3}\d{1,3}\b' # IPv4
- '\b[0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{12}\b' # UUIDs
attributes:
actions:
- key: enduser.id
action: delete
- key: net.peer.ip
action: delete
A August 2025 guide from Dash0 on mastering the OpenTelemetry redaction processor notes that the allowlist approach is the safer default for compliance-heavy environments because unknown attributes are removed by default rather than passed through. This aligns with the GDPR Article 25 obligation for data protection by default: if your system hasn't explicitly decided a field is safe, it shouldn't be stored.
Layer 3: IP address handling
IP addresses are personal data under GDPR and CCPA without exception in most practical contexts. The 2016 CJEU ruling in Breyer v. Germany (C-582/14) confirmed that even dynamic IP addresses can constitute personal data when the controller has the means to identify the data subject indirectly.
For error tracking, there are three defensible approaches:
-
Drop the IP entirely. For most error events, the originating IP contributes nothing to debugging. An exception type, a route, and a stack trace tell you what failed. The IP only tells you who triggered it — which is exactly the kind of linkage that makes the data personal.
-
Truncate to subnet level. Masking the last octet of IPv4 (or the last 80 bits of IPv6) is the approach Google Analytics used for IP anonymization. It preserves rough geographic utility while eliminating individual-level identification. The French data protection authority CNIL has recognized IP truncation as a privacy-protective measure for analytics, though not as full anonymization under the Article 29 Working Party's Opinion 05/2014 standard.
-
Hash with a rotating salt. A daily salt means a hashed IP cannot be used to track a user across days, and the raw IP is never stored. This preserves the ability to detect anomalous error rates from a single origin within a session window.
Databuddy's architecture never stores raw IP addresses — a design choice that eliminates this entire class of GDPR exposure. The cookieless analytics guide documents exactly how the platform processes visitor data without retaining linkable identifiers, making it a useful reference for teams designing their own error collection pipelines.
Layer 4: Stack trace content and source map security
Stack traces present two distinct privacy problems. First, if error messages embed user-supplied values ("Invalid email: alice@example.com was already taken"), those values land in your error log. Second, source maps can expose your entire application source code to anyone who can access your production JavaScript files.
For error message content: apply regex sanitization at the SDK layer (Layer 1) before the event is serialized. This is more reliable than post-hoc scrubbing because some error aggregation platforms truncate long strings before applying server-side rules, meaning a pattern applied to the truncated version misses a match at the original boundary.
For source maps: don't serve them publicly. The correct configuration for Webpack is devtool: 'hidden-source-map', which generates a .map file for upload to your error tracking service without embedding a //# sourceMappingURL comment that browsers can follow. As Sentry's own security team documented in a January 2025 analysis of exposed source maps, publicly accessible source maps can be used to reconstruct application logic, locate API endpoints, and identify hardcoded configuration values.
The workflow should be:
# Build with hidden source maps
NODE_ENV=production webpack --config webpack.prod.js
# Upload to error tracking service using service auth
error-client upload-sourcemaps ./dist --auth-token $ERROR_SERVICE_TOKEN
# Then DELETE local .map files before deploying build artifacts
rm -rf ./dist/*.map
Uploading to the error tracking service gives you symbolicated stack traces in your dashboard. Not publishing them to the web means attackers can't access them.
Defining what to collect and what to discard
Data minimization under GDPR Article 5(1)(c) isn't just about stripping obvious PII — it's about having a documented justification for every field you retain. For error tracking, a minimal viable event payload typically includes:
Retain:
- Exception type and class name
- Sanitized exception message (PII scrubbed)
- Stack trace with file paths and line numbers (symbolicated, not minified)
- HTTP method and route pattern (e.g., POST /api/users/:id, not POST /api/users/12345)
- HTTP response status code
- Browser/runtime name and major version
- Application version or git SHA
- Pseudonymous session or error group ID
- Timestamp (rounded to minute precision if user attribution is a concern)
Discard by default: - Raw IP address - Full URL with query parameters (may contain tokens, emails, search terms) - User email, name, or internal user ID - Request/response bodies - Cookie values and authentication headers - Full user-agent string (reduces risk of fingerprinting; major browser version is sufficient)
The OWASP Microservices Security Cheat Sheet expresses this as a pipeline requirement: the logging agent must filter or sanitize output before persisting, ensuring that sensitive data like PII, passwords, and API keys never appear in logs. This isn't optional hardening — it's baseline secure logging design.
For teams evaluating GDPR-compliant analytics tools, the same architectural principles that make page-view analytics privacy-safe also apply to error telemetry: collect what you need to diagnose problems, discard everything that links an error to an identifiable person.
Error grouping without user linkage
One concern teams raise when implementing aggressive PII stripping is error deduplication. "If I remove the user ID, how do I know whether 50 error events are from 50 users or one user hitting the same bug 50 times?"
The answer is fingerprint-based grouping, not user-based grouping. A fingerprint derived from the exception type, top stack frame, and route pattern produces a stable group identifier that's independent of who triggered the error. Sentry's fingerprinting system and equivalent mechanisms in other trackers support this natively.
For temporal correlation within a single session, a randomly generated ephemeral session token — not linked to the authenticated user identity — gives you enough information to see that errors A, B, and C occurred within the same browser session without knowing whose session it was. This is consistent with GDPR Article 4(5)'s definition of pseudonymization: the data can't be attributed to a specific natural person without additional information held separately.
Databuddy surfaces this in practice through its error tracking and API error handling documentation, which shows how to capture and group errors at the event level without persisting user-identifying fields.
Retention limits and automated deletion
GDPR Article 5(1)(e) — the storage limitation principle — requires that personal data be kept in identifiable form for no longer than necessary for the stated purpose. Error logs are collected to diagnose and fix software defects. Once a defect is resolved, the granular error events that led to its diagnosis have no ongoing purpose.
A practical retention policy for error telemetry:
- Raw error events: 30–90 days, automated deletion on expiry
- Aggregated error metrics (counts, rates by error type): Retained indefinitely — counts aren't personal data
- Resolved issues: Error events associated with a resolved issue group should be eligible for early deletion
- Security-relevant errors (authentication failures, rate limit violations): May warrant longer retention (up to 1 year) under a documented legitimate interest assessment, but these should be stored in a separate access-controlled log partition, not in your general error tracker
Automating this in your error tracking tooling is non-negotiable. Manual deletion processes are unreliable. Most hosted error trackers (including Sentry) support configurable event retention periods per project. For self-hosted or custom pipelines, cron-based deletion jobs tied to your documented retention schedule are the minimum viable control.
Teams running analytics platforms with full data ownership typically have more direct control over retention because the data doesn't leave their infrastructure to a third-party vendor's retention schedule.
Global Privacy Control and opt-out signals
The Global Privacy Control (GPC) specification — recognized as an enforceable opt-out signal under the CPRA's regulations (11 CCR §7025) — doesn't apply only to marketing trackers. Any platform that processes personal data for analytics purposes needs to handle the Sec-GPC: 1 request header.
For error tracking specifically, if a user has transmitted a GPC signal, the defensible position is to avoid collecting any error telemetry that contains personal data. Since a properly implemented privacy-first error tracker doesn't include personal data in its events by default, complying with GPC effectively means maintaining the same minimal collection posture rather than disabling error tracking entirely.
You can detect the signal server-side and adjust what's attached to error events:
// Node.js request handler example
const gpcEnabled = req.headers['sec-gpc'] === '1';
if (gpcEnabled) {
// Already minimal — ensure nothing extra is attached
errorContext = { route: req.route?.path, method: req.method };
} else {
// Standard minimal collection
errorContext = { route: req.route?.path, method: req.method };
// Add only non-identifying technical context
}
The check ends up being mostly a no-op when your default collection is already minimal — which is the point. For more on how GPC integrates with cookieless analytics GDPR compliance, the framework for analytics signals applies directly to error telemetry as well.
Documenting your data flows for Article 30 compliance
GDPR Article 30 requires controllers to maintain records of processing activities. For error tracking, this means your ROPA (Record of Processing Activities) needs to document:
- What data is collected in error events (field-level inventory)
- The legal basis for processing (legitimate interest: software quality assurance, typically)
- Retention periods and deletion mechanisms
- Third-party processors involved (your error tracking vendor) and their DPA status
- Technical measures for data minimization and PII scrubbing
This documentation requirement gives you an additional forcing function to maintain your minimal collection posture. If a field appears in your error events but can't be justified in your ROPA, it shouldn't be there.
Databuddy covers this accountability dimension in its GDPR compliance guide for web analytics, including the Article 28 Data Processing Agreement required when using any third-party analytics or error tracking processor.
Putting it together: a privacy-safe error tracking checklist
Here's a concise implementation checklist distilled from the architecture above:
Collection controls:
- SDK beforeSend / pre-export hook applies regex sanitization to exception messages and stack trace locals
- sendDefaultPii: false (or equivalent) prevents automatic PII attachment
- IP addresses are dropped or truncated before the event is serialized
- Full URLs are reduced to route patterns before logging
- Source maps are uploaded privately; .map files are deleted from public build artifacts
Pipeline controls: - OpenTelemetry Collector (or equivalent proxy) applies allowlist-based attribute redaction - Blocked-value regex patterns cover emails, IPs, card numbers, SSNs, and bearer tokens - Unknown attributes are dropped by default, not passed through
Storage and retention controls: - Error events are deleted on a 30–90 day rolling schedule, automated - Aggregated metrics (error counts, rates) are retained separately and indefinitely - Access to raw error events is role-gated and audited
Documentation: - ROPA entry covers error telemetry processing - DPA in place with any third-party error tracking vendor - Retention schedule documented and tested
The fundamental design principle is that debugging information and identifying information are separable. A stack trace doesn't need an email address. An exception type doesn't need a user ID. A route pattern doesn't need a full URL with query parameters. Once you internalize that separation, building a compliant error tracking pipeline is an engineering problem with well-defined solutions — not a tradeoff between observability and privacy.
For teams looking to consolidate error tracking alongside Web Vitals monitoring and feature flag management under a single privacy-first platform, Databuddy's architecture was built around the same data minimization principles described here: no cookies, no raw IP storage, full data ownership, and GDPR/CCPA compliance by default rather than by configuration.
Explore Databuddy's security and privacy settings to see how these controls are implemented in a production analytics stack, or review the data policy for a complete account of what flows through the platform and what doesn't.